Parser und Übersetzer
Übersetzung regulärer Ausdrücke
Ziel ist es, aus einem regulären Ausdruck z in systematischer Weise einen nichtdeterministischen endlichen Automaten N(z) zu konstruieren, der die von z erzeugte reguläre Sprache L(z) erkennt. Hierzu wird zuerst eine kontextfreie Grammatik für reguläre Ausdrücke angegeben. Basierend auf dieser Grammatik wird mithilfe der Recursive-Descent-Methode ein Übersetzer erzeugt, der einen regulären Ausdruck in den entsprechenden Automaten übersetzt. Die Übersetzungsaktionen entsprechen den Schritten, die im Abschnitt Konstruktion eines nichtdeterministischen endlichen Automaten aus einem regulären Ausdruck angegeben sind.
Grammatik
Zur Beschreibung regulärer Ausdrücke verwenden wir eine Grammatik in erweiterter Backus-Naur-Form (EBNF) mit folgenden Produktionen:
| expr | 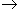 | term (| term)* |
| term | | factor factor* |
| factor | | atom ** |
| atom | | ( expr ) | literal |
| literal | | a | b | c | % |
Die Zeichen |, *, (, ) kommen einerseits in regulären Ausdrücken vor, sind also Terminalzeichen der Grammatik, andererseits aber auch Metazeichen zur Beschreibung der Grammatik. Zur Unterscheidung sind Terminalzeichen rot dargestellt, Metazeichen schwarz.
Die Grammatik berücksichtigt die Präzedenzregeln bei der Auswertung regulärer Ausdrücke: * bindet am stärksten, | bindet am schwächsten. Das in den regulären Ausdrücken verwendete Alphabet besteht hier nur aus den Zeichen a, b und c. Das Zeichen % steht für die leere Menge.
Es folgt das Programm.
Klasse RegExprCompiler
Die folgende, von der Klasse Parser abgeleitete Klasse RegExprCompiler übersetzt einen regulären Ausdruck in den zugehörigen nichtdeterministischen endlichen Automaten. Sie enthält für jede Produktionen der Grammatik eine entsprechende Funktion.
Der Automat wird bottom-up aus einfachen Automaten durch Parallel- und Hintereinanderschaltung sowie Abschlussbildung mittels der Funktionen parallel, concat und star der unten angegebenen Klasse Nfa aufgebaut.
from Nfa import *
# Compiler, der einen regulaeren Ausdruck in einen nichtdeterministischen
# endlichen Automaten (Klasse Nfa) uebersetzt (Bottom-up-Konstruktion)
def expr():
v=term()
while comes("|"):
consume()
v=v.parallel(term())
return v
def term():
v=factor()
while comesAnyOf("abc%("):
v=v.concat(factor())
return v
def factor():
v=atom()
while comes("*"):
consume()
v=v.star()
return v
def atom():
if comes("("):
consume()
v=expr()
match(")")
return v
else:
return literal()
def literal():
if comesAnyOf("abc%"):
a=getSymbol()
return Nfa(a) # Elementarautomat fuer Symbol a
else:
raise Exception("Buchstabe oder % erwartet")
Ein möglicher Aufruf des Übersetzers ist
v=compile("(a|b)*a", expr)
showErrorPosition()
print "Ergebnis:", v
Klassen State und Nfa
Zunächst folgt die Klasse State, die einen Zustand des Automaten darstellt. Bedingt durch die spezielle Konstruktion des Automaten ist die Klasse State sehr einfach aufgebaut.
Der Automat hat genau einen Endzustand. Dieser ist der einzige Zustand, der keinen Folgezustand hat. Alle anderen Zustände des Automaten haben einen oder zwei Folgezustände. Hat ein Zustand zwei Folgezustände, so sind beide Zustandsübergänge mit ε markiert.
Attribute der Klasse sind eine Liste nextstate mit bis zu zwei Einträgen, die Verweise auf die beiden möglichen Folgezustände enthält, sowie ein String symbol, der das Zeichen enthält, mit dem der Zustand in den Folgezustand übergeht. Ferner trägt jeder Zustand eine Nummer; diese wird mithilfe der Klassenvariable n bei jeder Erzeugung eines neuen Zustands hochgezählt. Für die Ausgabe und die Simulation des Automaten wird außerdem das boolesche Attribut marked benötigt.
# endlichen Automaten mit Epsilon-Uebergaengen (Epsilon wird
# durch $ dargestellt)
class State(object):
n=0 # Zaehler fuer Zustaende
def __init__(self, a="$"):
self.nextstate=[]
self.symbol=a
self.number=State.n
State.n+=1
self.marked=False
def setNextState(self, s):
self.nextstate.append(s)
def mark(self, b=True):
self.marked=b
def __str__(self):
return str(self.number)
Die folgende Klasse Nfa (nondeterministic finite automaton) repräsentiert einen nichtdeterministischen endlichen Automaten. Sie enthält einen Konstruktor zur Erzeugung eines Elementarautomaten für ein Alphabetzeichen a. Derselbe Konstruktor wird verwendet, um den Elementarautomaten für die leere Sprache, hier bezeichnet durch das Zeichen %, zu erzeugen. Da das Zeichen % nicht im Alphabet vorkommt, kann der Zustandsübergang mit dem Zeichen % nie ausgeführt werden, sodass der Automat wie gewünscht die leere Sprache akzeptiert.
Die Klasse enthält ferner Methoden zur Parallelschaltung und Hintereinanderschaltung des Automaten mit einem anderen Automaten sowie eine Methode für die Abschlussbildung, also die Anwendung des Stern-Operators, außerdem eine Methode zur Darstellung des Automaten als Tabelle der Übergangsrelation.
# Repraesentiert einen nichtdeterministischen endlichen Automaten mit
# Epsilon-Ubergaengen (nondeterministic finite automaton - NFA)
# und stellt die Operationen Parallel- und Hintereinanderschaltung
# sowie Abschluss zur Verfuegung
class Nfa(object):
# Elementarautomat mit Symbol a
def __init__(self, a):
self.startstate=State(a)
self.endstate=State()
self.startstate.setNextState(self.endstate)
# Schaltet Nfa self und Nfa other parallel
def parallel(self, other):
s=State()
t=State()
s.setNextState(self.startstate)
s.setNextState(other.startstate)
self.endstate.setNextState(t)
other.endstate.setNextState(t)
self.startstate=s
self.endstate=t
return self
# Verkettet Nfa self mit Nfa other
def concat(self, other):
self.endstate.setNextState(other.startstate)
self.endstate=other.endstate
return self
# Bildet den Abschluss Nfa self*
def star(self):
s=State()
t=State()
s.setNextState(self.startstate)
s.setNextState(t)
self.endstate.setNextState(s)
self.startstate=s
self.endstate=t
return self
# Loescht oder setzt alle Markierungen
def mark(self, b=True):
q=[self.startstate] # Queue
while q!=[]:
s=q.pop(0)
if s.marked!=b:
s.mark(b)
for t in s.nextstate:
q.append(t)
# Stellt den Automaten in Form einer Tabelle dar:
# Zustand / Zeichen / Folgezustaende unter diesem Zeichen
# Startzustand ist der erste Zustand, Endzustand ist
# derjenige Zustand, der keine Folgezustaende hat
def __str__(self):
self.mark(False) # alle Markierungen entfernen
w=""
q=[self.startstate] # Queue
while q!=[]:
s=q.pop(0)
if not s.marked:
s.mark()
w+="\n"+str(s)+" "+s.symbol+" "
for t in s.nextstate:
w+=str(t)+" "
q.append(t)
return w+"\n"
Zusammenfassung
Die Struktur regulärer Ausdrücke ist durch die Grammatik für reguläre Ausdrücke vorgegeben. Aus dieser Grammatik haben wir mit der Recursive-Descent-Methode einen Übersetzer für reguläre Ausdrücke konstruiert. Ziel der Übersetzung eines bestimmten regulären Ausdrucks ist ein zugehöriger nichtdeterministischer endlicher Automat, der die von dem regulären Ausdruck erzeugte Sprache erkennt.
Mithilfe des so konstruierten Automaten lässt sich feststellen, ob ein bestimmtes Wort w von einem gegebenen regulären Ausdruck erzeugt wird (siehe Simulation eines nichtdeterministischen endlichen Automaten).
Weiter mit: [Simulation eines nichtdeterministischen endlichen Automaten] oder [up]
H.W. Lang mail@hwlang.de Impressum Datenschutz
Created: 24.08.2012 Updated: 17.02.2023
Diese Webseiten sind während meiner Lehrtätigkeit an der Hochschule Flensburg entstanden