Textsuche
String-Matching-Automaten
Das Textsuchproblem lässt sich zurückführen auf die Erkennung von Sprachen mit nichtdeterministischen Automaten, einem zentralen Thema der theoretischen Informatik. Es zeigt sich, dass der Shift-And-Algorithmus und der Knuth-Morris-Pratt-Algorithmus sich als geschickte Implementierungen dieses Ansatzes auffassen lassen.
Konstruktion von String-Matching-Automaten
Sei A = {a0, ..., ak-1} ein Alphabet und p = p0 ... pm-1 ein Muster sowie ferner t ein Text über A. Die Aufgabe eines Textsuchverfahrens besteht darin, alle Vorkommen des Musters p im Text t zu suchen.
Offenbar erhält man einen solches Verfahren, indem man für den regulären Ausdruck A*p einen zugehörigen nichtdeterministischen endlichen Automaten konstruiert und diesen mit dem Text t als Eingabe simuliert.1) Es ist lediglich noch eine Ausgabefunktion hinzuzufügen, die jedes Mal ein Vorkommen des Musters im Text meldet, wenn der Automat einen Endzustand erreicht.
Statt der schematischen Methode zur Konstruktion eines Automaten aus einem regulären Ausdruck wird folgende vereinfachte Konstruktion angewendet:
Der Anfangszustand geht mit allen Zeichen aus A in sich selbst über, außerdem geht vom Anfangszustand eine Kette von Zustandsübergängen mit den Zeichen p0, p1, ..., pm-1 aus. Der letzte Zustand dieser Kette ist der Endzustand.
Wir bezeichnen einen solchen vereinfacht konstruierten nichtdeterministischen endlichen Automaten als String-Matching-Automaten.
Beispiel: Das folgende Bild 1 zeigt den vereinfacht konstruierten nichtdeterministischen endlichen Automaten für das Muster p = aaba.
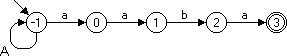
Bild 1: String-Matching-Automat für p = aaba
Simulation von String-Matching-Automaten
Die Simulation eines nichtdeterministischen endlichen Automaten ist im Allgemeinen nicht sehr effizient, denn es müssen bei jedem eingelesenen Zeichen alle markierten Zustände behandelt werden. Wenn etwa das Muster am und der Eingabetext an ist, sind nach kurzer Zeit m Zustände markiert, d.h. es sind bei jedem gelesenen Zeichen m Zustandsübergänge zu behandeln. Somit ergibt sich eine Komplexität der Simulation von Θ(n·m), also keine Verbesserung gegenüber dem naiven Algorithmus.
Ein effizienter Algorithmus ergibt sich durch Konstruktion eines zu dem String-Matching-Automaten äquivalenten deterministischen Automaten. Dieser verarbeitet jedes gelesene Eingabezeichen in konstanter Zeit, sodass sich eine Zeitkomplexität von Θ(n) ergibt.
Der Speicherbedarf eines entsprechenden deterministischen Automaten beträgt jedoch Θ(m·k). Denn die Anzahl der Zustände des Automaten ist etwa gleich m, und die Tabelle für die möglichen Zustandsübergänge hat in jedem Zustand k Einträge (m Länge des Musters, k Größe des Alphabets). Entsprechend hohe Zeitkomplexität hat auch das Verfahren zur Konstruktion des deterministischen Automaten.
Da es sich bei String-Matching-Automaten um sehr spezielle nichtdeterministische endliche Automaten handelt, stellt sich die Frage, ob sich ein solcher Automat nicht auf andere Art effizienter simulieren lässt als ein allgemeiner nichtdeterministischer endlicher Automat. Tatsächlich ist dies der Fall; sowohl der Knuth-Morris-Pratt-Algorithmus als auch der Shift-And-Algorithmus basieren auf einer geschickten Simulation eines String-Matching-Automaten.
Shift-And-Algorithmus
Der Shift-And-Algorithmus stellt eine Simulation eines String-Matching-Automaten dar. Die Funktionsweise ist die folgende:
Die bei der normalen Simulation eines nichtdeterministischen endlichen Automaten folgende Zustandsmarkierung bei Eingabe eines Zeichens a ∈ A ergibt sich, indem in einem ersten Schritt alle Markierungen um 1 nach rechts geschoben werden und der Anfangszustand erneut markiert wird. Korrekt markiert sind jetzt allerdings außer dem Anfangszustand nur diejenigen Zustände, zu denen tatsächlich ein mit a bezeichneter Pfeil hinführt. Im zweiten Schritt werden daher alle anderen Markierungen gelöscht.
Implementierung mit Bitvektoren
Die Zustandsmarkierung des Automaten lässt sich in einem Bitvektor der Länge m darstellen. Hierbei ist Bit i gleich 1, wenn Zustand i markiert ist, und sonst 0. Der Anfangszustand ist immer markiert, er braucht daher nicht in dem Bitvektor repräsentiert zu sein. Daher wird er hier mit -1 nummeriert, sodass die Nummerierung der folgenden Zustände zur Indizierung des Bitvektors passt.
In Schritt 1 wird der Bitvektor um eine Position nach rechts geschoben, wobei an Position 0 eine 1 nachgezogen wird (entsprechend der Markierung des Zustands -1).
In Schritt 2 erfolgt das Ausblenden der nunmehr falsch markierten Bitstellen, indem ein logisches Und mit einem Bitvektor durchgeführt wird, der an den richtigen Stellen Einsen trägt. Dieser Bitvektor ist der charakteristische Vektor für das Eingabezeichen a; er trägt eine 1 an Position i, wenn pi = a ist.
Beispiel: Das folgende Bild 2 zeigt die Markierung des Automaten nach dem Einlesen des Wortes aa. Darunter ist der zugehörige Bitvektor angegeben. Die Markierung des Automaten bei Einlesen des Zeichens b ergibt sich durch Rechtsschieben des Bitvektors und Nachziehen einer 1 sowie anschließender Und-Verknüpfung mit dem charakteristischen Bitvektor von b.
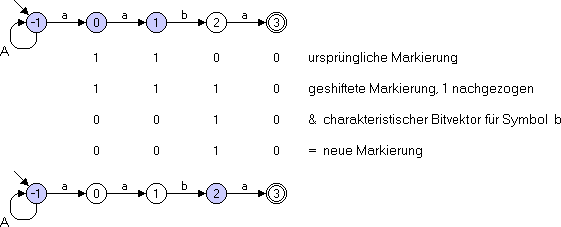
Bild 2: Neue Zustandsmarkierungen nach Einlesen des Zeichens b
Wenn die verwendeten Bitvektoren in ein Maschinenwort passen, lassen sich die Schiebe- und die Und-Operation in jeweils einem Schritt durchführen. Dies ist pro gelesenem Textzeichen zu rechnen, sodass sich für die Suchphase insgesamt eine Komplexität von Θ(n) ergibt.
In einem Vorlauf muss für jedes im Muster vorkommende Zeichen der charakteristische Vektor berechnet werden; dies benötigt Zeit Θ(m). Die charakteristischen Vektoren aller anderen Zeichen des Alphabets sind 0.
Knuth-Morris-Pratt-Algorithmus
Auch der Knuth-Morris-Pratt-Algorithmus stellt eine Simulation eines String-Matching-Automaten dar. Der Ansatz ist der folgende:
Es wird nur die jeweils am weitesten nach rechts vorgerückte Markierung in der normalen Simulation eines nichtdeterministischen endlichen Automaten betrachtet. Interessanterweise sind durch diese Markierung alle anderen Markierungen eindeutig bestimmt.
Die Positionen der jeweils anderen Markierungen lassen sich im voraus aus der Struktur des Musters berechnen. Denn wenn ein Zustand markiert ist, weiß man, welches die zuletzt eingelesenen Zeichen gewesen sein müssen, die zur Markierung dieses Zustands geführt haben. Dann weiß man auch, welche der vorhergehenden Zustände markiert sind.
In folgendem Beispiel etwa ist der Zustand 4 markiert. Somit sind die zuletzt eingelesenen Zeichen abab gewesen. D.h. die beiden letzten eingelesenen Zeichen sind ab gewesen, also ist auch Zustand 2 markiert. Zustand 0 ist immer markiert.
Die Positionen der Markierungen werden in einem Array b gehalten, das die folgende Information enthält:
Wenn Zustand i markiert ist, dann ist b[i] der nach links gesehen nächste markierte Zustand.
Beispiel: Bild 3 zeigt den nichtdeterministischen endlichen Automaten für das Muster p = ababa. Unter jedem Zustand i ist der Wert b[i] angegeben.
Zustand 4 trägt die am weitesten nach rechts vorgerückte Markierung. Der nächste markierte Zustand ist b[4]=2, der darauf folgende ist b[2]=0.

Bild 3: Werte des Arrays b
Die Simulation geschieht nun, indem jeweils geprüft wird, ob von dem am weitesten rechts befindlichen markierten Zustand i aus ein Zustandsübergang mit dem gelesenen Zeichen a möglich ist. Wenn dies der Fall ist, wird dieser Zustandsübergang vollzogen und das nächste Zeichen gelesen. Wenn nicht, wird die Markierung gelöscht und stattdessen Zustand b[i] markiert. Von diesem Zustand aus wird ein neuer Versuch unternommen, mit dem Zeichen a einen Zustandsübergang zu machen usw.
Spätestens im Anfangszustand gelingt der Zustandsübergang, da vom Anfangszustand aus unter jedem Eingabezeichen ein Zustandsübergang möglich ist.
Suchen von mehreren Mustern
Eine Verallgemeinerung des Textsuchproblems besteht darin, gleichzeitig nach mehreren Mustern zu suchen. Im Algorithmus von Aho und Corasick [AC 75] wird dieses Problem ebenfalls durch Simulation eines String-Matching-Automaten gelöst. Anhand des in [AC 75] angegebenen Beispiels wird das Verfahren im Folgenden skizziert.
Sei P = {he, she, his, hers} die Menge der Muster. Der zugehörige String-Matching-Automat ist in Bild 4 abgebildet. Nach Eingabe der Zeichenfolge sh ergibt die Simulation des Automaten die dargestellte Zustandsmarkierung.
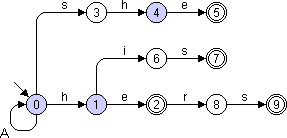
Bild 4: String-Matching-Automat für mehrere Muster
Genau wie beim Knuth-Morris-Pratt-Algorithmus wird die am weitesten nach rechts vorgerückte Markierung betrachtet. Wird diese Markierung gelöscht, weil von diesem Zustand aus mit dem eingelesenen Zeichen kein Zustandsübergang möglich ist, so wird versucht, mit der nächsten Markierung den entsprechenden Zustandsübergang durchzuführen usw. Spätestens beim Anfangszustand gelingt der Zustandsübergang, da vom Anfangszustand aus unter jedem Eingabezeichen ein Zustandsübergang möglich ist.
Im Beispiel von Bild 4 kann die Markierung von Zustand 4 unter dem Eingabezeichen i nicht vorrücken und wird daher gelöscht. Nun wird versucht, mit dem nächsten markierten Zustand, hier 1, unter dem Eingabezeichen i einen Zustandsübergang zu machen. Dies führt hier zum Erfolg, die Markierung rückt auf Zustand 6 vor.
Auch hier bestimmt die am weitesten rechts befindliche Markierung eindeutig alle anderen Markierungen. Befindet sich wie im Beispiel die am weitesten nach rechts vorgerückte Markierung auf Zustand 4, so sind die letzten eingelesenen Zeichen sh gewesen. Somit ist auch Zustand 1 markiert. Zustand 0 ist immer markiert.
Es kann also ein Array b im voraus berechnet werden, das die folgende Information enthält: Wenn Zustand i markiert ist, so ist b[i] der nächste markierte Zustand.
Im Beispiel ist b[4]=1 und b[1]=0; b[0] wird auf -1 gesetzt.
Die Struktur des Automaten entspricht einem sogenannten Trie. Ein Trie ist ein Baum mit Kantenmarkierung, dessen an der Wurzel beginnenden Pfade mit den Präfixen einer Menge von Wörtern markiert sind, wobei keine verschiedenen Pfade die gleiche Markierung tragen.
Literatur
[AC 75] A.V. Aho, M.J. Corasick: Efficient String Matching: An Aid to Bibliographic Search. Communications of the ACM, 18, 6, 333-340 (1975)
[Lan 12] H.W. Lang: Algorithmen in Java. 3. Auflage, Oldenbourg (2012)
String-Matching-Algorithmen werden sehr ausführlich auch in meinem Buch über Algorithmen behandelt, so die bekannten Verfahren von Knuth-Morris-Pratt und Boyer-Moore, aber auch noch eine ganze Reihe anderer interessanter Verfahren.
Weitere Themen des Buches: Sortieren, Graphenalgorithmen, Arithmetik, Codierung, Kryptografie, parallele Sortieralgorithmen.
Themen des Buches: Sortieren, Graphenalgorithmen, Arithmetik, Codierung, Kryptografie, parallele Sortieralgorithmen.

1) In dem regulären Ausdruck steht A für (a0 | a1 | ... | ak-1).
Weiter mit: [up]
H.W. Lang mail@hwlang.de Impressum Datenschutz
Created: 18.02.2002 Updated: 05.02.2023
Diese Webseiten sind während meiner Lehrtätigkeit an der Hochschule Flensburg entstanden