Parser und Übersetzer
Recursive-Descent-Methode
Die Methode der Übersetzung durch rekursiven Abstieg (engl.: recursive descent) wird im Folgenden anhand von Beispielen dargestellt. Das erste Beispiel ist bewusst sehr einfach gewählt, um das Prinzip der Recursive-Descent-Methode darzustellen.
Im ersten Beispiel soll ein Parser für einstellige ganze Zahlen mit oder ohne Vorzeichen erstellt werden. Ein Parser ist ein Programm, das eine Zeichenreihe in ihre syntaktischen Bestandteile zerlegt und erkennt, ob die Zeichenreihe den vorgegebenen Syntaxregeln entspricht oder nicht.
Syntax
Die Syntaxregeln werden formal durch eine kontextfreie Grammatik angegeben.
Die Zahlen sollen zunächst nur aus einer Ziffer bestehen. Wir benutzen folgende Grammatik G = (V, T, P, S); es sind
| V = | { number, sign, digit } die Menge der Variablen, | ||||||||||
| T = | { 0, ..., 9, +, - } die Menge der Terminalzeichen, | ||||||||||
| P : |
| ||||||||||
| die Produktionen und | |||||||||||
| S = | number das Startsymbol. |
Syntaktisch korrekte Zahlen entsprechend dieser Grammatik sind also beispielsweise 3, -5, +0 oder 6. Bild 1 zeigt den Ableitungsbaum für die Zahl -5.
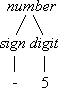
Bild 1: Ableitungsbaum für - 5
Recursive-Descent-Parser
Grundlage für die Konstruktion eines Recursive-Descent-Parsers ist eine kontextfreie Grammatik. Die Grammatik muss bestimmte Eigenschaften haben; diese werden im Folgenden später noch herausgearbeitet.
Die Grammatik ist in der Weise gegeben, dass Produktionen mit gleicher linker Seite zu einer Produktion mit mehreren Alternativen auf der rechten Seite zusammengefasst sind.
Bei der Recursive-Descent-Methode wird für jede dieser Produktionen eine Funktion geschrieben. Die Funktion erhält denselben Namen wie die Variable auf der linken Seite der Produktion. Auf diese Weise wird erreicht, dass die Grammatik sich sozusagen "selbst ausführt" und das Eingabewort auf das Startsymbol reduziert.
In der Funktion werden alle Alternativen, die auf der rechten Seite der Produktion vorkommen, durch Fallunterscheidung getrennt behandelt. Eine Alternative wird implementiert, indem für jede dort vorkommende Variable ein entsprechender Funktionsaufruf durchgeführt wird, und für jedes dort vorkommende Terminalzeichen das entsprechende Zeichen vom Eingabewort abgearbeitet wird.
Grundlage der Entscheidung, welche Alternative angewendet wird, ist das nächste abzuarbeitende Zeichen des Eingabewortes (der "Lookahead"). Die Grammatik muss so gestaltet sein, dass aufgrund des Lookaheads immer eine Entscheidung möglich ist.
Die Funktion für die Produktion number  sign digit ist sehr einfach. Da die rechte Seite nicht aus mehreren Alternativen besteht, ist keine Fallunterscheidung erforderlich. Die Implementierung besteht lediglich aus einem Funktionsaufruf für sign gefolgt von einem Funktionsaufruf für digit.
sign digit ist sehr einfach. Da die rechte Seite nicht aus mehreren Alternativen besteht, ist keine Fallunterscheidung erforderlich. Die Implementierung besteht lediglich aus einem Funktionsaufruf für sign gefolgt von einem Funktionsaufruf für digit.
{
sign();
digit();
}
Die Funktion für die Produktion sign + | - | ε muss die drei Alternativen der Produktion unterscheiden. Wenn das nächste Zeichen des Eingabewortes ein Pluszeichen ist, wird die erste Alternative angewendet, wenn es ein Minuszeichen ist, die zweite, und ansonsten die dritte.
Die Funktion comes prüft, mit welchem Zeichen das (verbliebene) Eingabewort anfängt; die Funktion match arbeitet das Zeichen ab. Die genaue Implementation dieser Funktionen ist weiter unten angegeben.
{
if (comes("+")) // Produktion sign -> + anwenden
match("+");
else if (comes("-")) // Produktion sign -> - anwenden
match("-");
else; // Produktion sign -> epsilon anwenden: tue nichts
}
Die Funktion für die Produktion der Variablen digit lässt sich in ähnlicher Weise durch zehn Fallunterscheidungen implementieren. Dies mag umständlich erscheinen, aber wir implementieren damit streng die Regeln der Grammatik. Es ist gute Praxis, sich nicht zu "Optimierungen" verleiten zu lassen, sondern die Grammatik exakt nachzubilden.
{
if (comes("0"))
match("0");
else if (comes("1"))
match("1");
else if (comes("2"))
match("2");
else if (comes("3"))
match("3");
else if (comes("4"))
match("4");
else if (comes("5"))
match("5");
else if (comes("6"))
match("6");
else if (comes("7"))
match("7");
else if (comes("8"))
match("8");
else if (comes("9"))
match("9");
else
throw new RuntimeException("Ziffer erwartet");
}
Klasse SimpleNumberParser
Die angegebenen drei Funktionen sind eingebettet in eine Klasse SimpleNumberParser, die von einer abstrakten Basisklasse Parser abgeleitet ist. Die Klasse Parser enthält eine Funktion parse, in der eine zunächst abstrakte Funktion startSymbol aufgerufen wird. Diese wird in der abgeleiteten Klasse SimpleNumberParser implementiert, indem die Startsymbol-Funktion number aufgerufen wird.
Das zu analysierende Eingabewort inputstring sowie die grundlegenden Funktionen wie etwa comes, match und andere sind einer abstrakten Klasse ParserFunctions implementiert, von der wiederum die Klasse Parser abgeleitet ist.
Wir verwenden diese mehrstufige Klassenhierarchie, weil wir später von der Klasse ParserFunctions auch eine abstrakte Klasse Compiler und von dieser wiederum konkrete Compiler ableiten wollen, um Eingabewörter nicht nur syntaktisch zu prüfen, sondern sie gleichzeitig auch noch zu übersetzen.
{
// Startsymbol ist number
@Override
protected void startSymbol()
{
number();
}
// number -> sign digit
private void number()
{
sign();
digit();
}
// sign -> + | - | epsilon
private void sign()
{
if (comes("+")) // Produktion sign -> + anwenden
match("+");
else if (comes("-")) // Produktion sign -> - anwenden
match("-");
else; // Produktion sign -> epsilon anwenden: tue nichts
}
// digit -> 0 | 1 | ... | 9
private void digit()
{
if (comes("0"))
match("0");
else if (comes("1"))
match("1");
else if (comes("2"))
match("2");
else if (comes("3"))
match("3");
else if (comes("4"))
match("4");
else if (comes("5"))
match("5");
else if (comes("6"))
match("6");
else if (comes("7"))
match("7");
else if (comes("8"))
match("8");
else if (comes("9"))
match("9");
else
throw new RuntimeException("Ziffer erwartet");
}
// Test
public static void main(String[] args)
{
Parser p=new SimpleNumberParser();
String x="+5";
p.parse(x);
System.out.println(x);
System.out.println(p.errorPointer());
System.out.println(p.errormessage);
}
} // end class SimpleNumberParser
Im Hauptprogramm wird zunächst ein Objekt p vom Typ SimpleNumberParser erzeugt und ein Eingabewort x festgelegt. Dieses wird mit p.parse(x) analysiert. Anschließend wird entweder "ok" oder eine Fehlermeldung ausgegeben und die Position des Fehlers angezeigt.
Basisklasse Parser
Alle konkreten Parser, die eine bestimmte Grammatik zugrunde legen, werden von der abstrakten Klasse Parser abgeleitet. Die Klasse Parser greift wiederum auf eine abstrakte Klasse ParserFunctions zurück.
Zusammenfassung
Bei der Recursive-Descent-Methode wird die gegebene kontextfreie Grammatik direkt in einen Parser überführt.
Dies geschieht, indem für jede Produktion der Grammatik eine Funktion geschrieben wird. Die Funktion erhält denselben Namen wie die Variable, die auf der linken Seite der Produktion steht. In der Funktion werden alle auf der rechten Seite der Produktion stehenden Alternativen durch Fallunterscheidung getrennt implementiert.
Eine Alternative auf der rechten Seite einer Produktion wird implementiert, indem für jede dort vorkommende Variable die entsprechende Funktion aufgerufen wird. Für jedes Terminalzeichen wird die Funktion match aufgerufen.
Die Fallunterscheidung, welche Alternative einer Produktion anzuwenden ist, wird anhand des ersten Zeichens des jeweils verbliebenen, noch nicht abgearbeiteten Eingabewortes durchgeführt.
Weiter mit: [Parser für Additions-Subtraktions-Ausdrücke] oder [up]
H.W. Lang mail@hwlang.de Impressum Datenschutz
Created: 23.11.2011 Updated: 17.02.2023
Diese Webseiten sind während meiner Lehrtätigkeit an der Hochschule Flensburg entstanden