Textsuche
Boyer-Moore-Algorithmus
Idee
Der Algorithmus von Boyer und Moore [BM 77] vergleicht das Muster von rechts nach links mit dem Text. Ist bereits das erste verglichene Textzeichen ein Zeichen, das im Muster überhaupt nicht vorkommt, so kann das Muster um m Positionen hinter dieses Zeichen weitergeschoben werden. Das folgende Beispiel verdeutlicht diese Situation.
Beispiel:
Der erste Vergleich d-c an Position 4 liefert einen Mismatch. Das Textzeichen d kommt im Muster überhaupt nicht vor. Daher kann das Muster an keiner der Positionen 0, ..., 4 übereinstimmen, denn alle zugehörigen Fenster enthalten das d. Das Muster kann bis Position 5 weitergeschoben werden.
Der günstigste Fall für den Boyer-Moore-Algorithmus tritt also ein, wenn jedes Mal beim ersten Vergleich ein Textzeichen gefunden wird, das im Muster nicht vorkommt. Dann benötigt der Algorithmus nur O(n/m) Vergleiche.
Schlechtes-Zeichen-Strategie
Die eben beschriebene Vorgehensweise wird als Schlechtes-Zeichen-Strategie (bad character heuristics) bezeichnet. Sie kann auch angewendet werden, wenn das gefundene Zeichen zwar schlecht ist, also zu einem Mismatch führt, aber an anderer Stelle im Muster vorkommt. Dann allerdings kann das Muster nur so weit geschoben werden, bis dieses Vorkommen auf das Textzeichen ausgerichtet ist. Im nächsten Beispiel tritt diese Situation auf.
Beispiel:
Der Vergleich b-c liefert einen Mismatch. Das Textzeichen b kommt im Muster an Position 0 und an Position 2 vor. Das Muster kann so weit geschoben werden, dass das letzte b des Musters auf das Textzeichen b ausgerichtet ist, also bis Position 2.
Gutes-Ende-Strategie
Nicht immer liefert die Schlechtes-Zeichen-Strategie ein gutes Ergebnis. In folgender Situation hat der Vergleich a-b einen Mismatch ergeben. Eine Ausrichtung des letzten Vorkommens des a im Muster auf das a im Text würde eine negative Verschiebung ergeben. Man könnte sich so behelfen, dass man stattdessen um 1 schiebt. Besser ist es, in diesem Fall die größtmögliche Schiebedistanz aus der Struktur des Musters abzuleiten. Die Schiebedistanz richtet sich danach, ob das Suffix, das übereingestimmt hat, noch an anderer Stelle im Muster vorkommt. Diese Vorgehensweise heißt Gutes-Ende-Strategie (good suffix heuristics).
Beispiel:
Das Suffix ab hat bereits übereingestimmt. Das Muster kann so weit geschoben werden, bis das nächste Vorkommen von ab im Muster auf die Textzeichen ab ausgerichtet ist, also bis Position 2.
In folgender Situation hat das Suffix ab bereits übereingestimmt. Es gibt im Muster kein weiteres Vorkommen von ab. Daher kann das Muster hinter das ab geschoben werden, also bis Position 5.
Beispiel:
In folgender Situation hat das Suffix bab übereingestimmt. Es gibt im Muster kein weiteres Vorkommen von bab. Aber in diesem Fall kann das Muster nicht wie eben an Position 5 geschoben werden, sondern nur bis Position 3, da ein Präfix des Musters (ab) mit einem Teil des übereinstimmenden Suffixes bab übereinstimmt. Wir bezeichnen diese Situation als Fall 2 der Gutes-Ende-Strategie.
Beispiel:
Das Muster wird jeweils um die längere der beiden Distanzen geschoben, die sich aus der Gutes-Ende- bzw. der Schlechtes-Zeichen-Strategie ergeben.
Vorlauf für die Schlechtes-Zeichen-Strategie
Für die Schlechtes-Zeichen-Strategie wird eine Funktion occ benötigt, die für jedes Alphabetzeichen die Position seines letzten Vorkommens im Muster liefert, bzw. -1, falls das Zeichen im Muster überhaupt nicht vorkommt.
Definition: Sei A das zugrunde liegende Alphabet.
Die Occurrence-Funktion occ : A* × A → ℤ ist wie folgt definiert:
Sei p ∈ A* mit p = p0 ... pm-1 das Muster und a ∈ A ein Alphabetzeichen. Dann ist
occ(p, a) = max{ j | pj = a}.
Hierbei wird max( ∅ ) = -1 gesetzt.
Beispiel:
- occ(text, x) = 2
- occ(text, t) = 3
Das letzte Vorkommen des Zeichens x in dem Wort text ist an Position 2. Das Zeichen t kommt an den Positionen 0 und 3 vor; das letzte Vorkommen ist an Position 3.
Die Occurrence-Funktion für ein bestimmtes Muster p wird in einem Array occ gespeichert, das durch die Alphabetzeichen indiziert wird. Für jedes Zeichen a ∈ A enthält occ[a] den entsprechenden Funktionswert occ(p, a).
Folgende Funktion bmInitocc berechnet zu gegebenem Muster p die Occurrence-Funktion.
Vorlauf für die Schlechtes-Zeichen-Strategie
{
int j;
char a;
for (a=0; a<alphabetsize; a++)
occ[a]=-1;
for (j=0; j<m; j++)
{
a=p[j];
occ[a]=j;
}
}
Es ist in Java möglich, das Array occ durch a vom Typ char zu indizieren, da char ohne explizite Konversion in int umgewandelt wird.
Vorlauf für die Gutes-Ende-Strategie
Für die Gutes-Ende-Strategie wird ein Array s benötigt, das für jedes i angibt, um wie viel das Muster geschoben werden kann, wenn ein Mismatch an Position i-1 auftritt, d.h. wenn das an Position i beginnende Suffix übereingestimmt hat. Um diese Schiebedistanz zu bestimmen, sind zwei unterschiedliche Fälle zu betrachten.
Fall 1: Das übereinstimmende Suffix kommt noch an anderer Stelle im Muster vor (Bild 1).
Fall 2: Nur ein Teil des übereinstimmenden Suffixes kommt am Anfang des Musters vor (Bild 2).
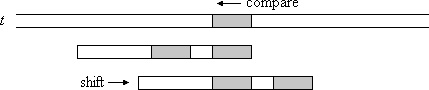
Bild 1: Das übereinstimmende Suffix (grau) kommt noch an anderer Stelle im Muster vor
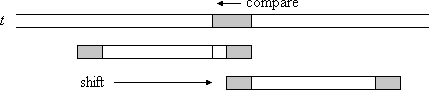
Bild 2: Ein Teil des übereinstimmenden Suffixes kommt am Anfang des Musters vor
Fall 1:
Die Situation ist ähnlich wie beim Knuth-Morris-Pratt-Vorlauf. Das übereinstimmende Suffix stellt einen Rand eines Suffixes des Musters dar. Zu jedem Suffix des Musters sind also die Ränder zu bestimmen. Benötigt wird jedoch die inverse Zuordnung zwischen einem gegebenen Rand und dem kürzesten Suffix des Musters, das diesen Rand hat.
Zusätzlich ist noch gefordert, dass der Rand sich nicht nach links fortsetzen lässt, denn dann würde es nach Verschiebung des Musters zu einem erneuten Mismatch kommen.
In folgendem ersten Teil des Vorlaufalgorithmus wird ein Array f berechnet. Für ein an Position i beginnendes Suffix des Musters enthält der Eintrag f[i] die Anfangsposition seines breitesten Randes. Für das Suffix ε, das an Position m beginnt, wird f[m] = m+1 gesetzt.
Genau wie beim Knuth-Morris-Pratt-Vorlauf wird ein Rand berechnet, indem geprüft wird, ob sich ein schon berechneter kürzerer Rand fortsetzen lässt.
Interessant ist hier wiederum auch der Fall, wenn sich ein Rand nicht fortsetzen lässt, denn dies bedeutet eine aussichtsreiche Verschiebung des Musters bei einem Mismatch. Es wird daher die zugehörige Schiebedistanz in ein Array s eingetragen – vorausgesetzt, dass der entsprechende Eintrag nicht schon belegt ist (dies ist dann der Fall, wenn ein kürzeres Suffix schon denselben Rand hatte).
Vorlauf für die Gutes-Ende-Strategie Fall 1
{
int i=m, j=m+1;
f[i]=j;
while (i>0)
{
while (j<=m && p[i-1]!=p[j-1])
{
if (s[j]==0) s[j]=j-i;
j=f[j];
}
i--; j--;
f[i]=j;
}
}
Eine Visualisierung der Ausführung dieses Algorithmus steht in [3] zur Verfügung. Das folgende Beispiel zeigt die Belegung für das Array f und die bis hierhin berechneten Einträge im Array s.
Beispiel:
Das an Position 2 beginnende Suffix babab hat als breitesten Rand bab, dieser beginnt an Position 4. Daher ist f[2] = 4. Das an Position 5 beginnende Suffix ab hat als breitesten Rand ε, dieser beginnt an Position 7. Daher ist f[5] = 7.
Für die Belegung des Arrays s sind die Ränder maßgebend, die sich nicht nach links fortsetzen lassen.
Das an Position 2 beginnende Suffix babab hat den Rand bab, dieser beginnt an Position 4. Dieser Rand lässt sich nicht fortsetzen, denn es ist p[1] ≠ p[3]. Die Differenz 4 – 2 = 2 ist daher die Schiebedistanz, wenn bab übereingestimmt hat und dann ein Mismatch auftritt. Somit ist s[4] = 2.
Das an Position 2 beginnende Suffix babab hat auch noch den Rand b, dieser beginnt an Position 6. Auch dieser Rand lässt sich nicht fortsetzen. Daher wird die Schiebedistanz 6 – 2 = 4 an Position 6 eingetragen.
Der Eintrag s[7] = 1 kommt zustande, weil das an Position 6 beginnende Suffix b den an Position 7 beginnenden Rand ε hat und sich dieser nicht fortsetzen lässt.
Fall 2:
Der Eintrag f[0] enthält die Anfangsposition des breitesten Randes des ganzen Musters. In obigem Beispiel also 5, da der Rand ab an Position 5 beginnt. Tritt das "gute Ende", also das übereinstimmende Suffix des Musters nicht an anderer Stelle im Muster auf, wie eben in Fall 1 dargestellt, so kann das Muster so weit geschoben werden, wie es sein Rand zulässt. Maßgebend ist dabei jeweils der breiteste Rand, sofern er nicht breiter als das übereinstimmende Suffix ist.
Im folgenden zweiten Teil des Vorlaufalgorithmus werden alle noch freien Einträge des Arrays s belegt. Eingetragen wird zunächst überall die Anfangsposition des breitesten Randes des Musters, diese ist j = f[0]. Ab Position i = j wird auf den nächstschmaleren Rand f[j] umgeschaltet usw.
Vorlauf für die Gutes-Ende-Strategie Fall 2
{
int i, j;
j=f[0];
for (i=0; i<=m; i++)
{
if (s[i]==0) s[i]=j;
if (i==j) j=f[j];
}
}
Eine Visualisierung der Ausführung dieses Algorithmus steht in [3] zur Verfügung. Folgendes Beispiel zeigt die endgültige Belegung des Arrays s.
Beispiel:
Der gesamte Vorlaufalgorithmus des Boyer-Moore-Verfahrens besteht aus der Berechnung der Occurrence-Funktion und den beiden eben betrachteten Teilen.
Boyer-Moore-Vorlauf
{
int[] f=new int[m+1];
bmInitocc();
bmPreprocess1();
bmPreprocess2();
}
Suchalgorithmus
Der Suchalgorithmus vergleicht die Zeichen des Musters von rechts nach links mit dem Text. Bei vollständiger Übereinstimmung wird das Muster anschließend so weit geschoben, wie es sein Rand zulässt. Nach einem Mismatch wird das Muster um das Maximum der Werte geschoben, die sich aus der Gutes-Ende- und der Schlechtes-Zeichen-Strategie ergeben.
Boyer-Moore-Suchalgorithmus
{
int i=0, j;
while (i<=n-m)
{
j=m-1;
while (j>=0 && p[j]==t[i+j]) j--;
if (j<0)
{
report(i);
i+=s[0];
}
else
i+=Math.max(s[j+1], j-occ[t[i+j]]);
}
}
Analyse
Unter der Bedingung, dass das Muster im Text nicht oder nur eine konstante Anzahl von Malen vorkommt, führt der Boyer-Moore-Algorithmus in der Suchphase im schlechtesten Fall O(n) Vergleiche durch. Der Beweis hierfür ist allerdings recht schwierig.
Im allgemeinen Fall sind Θ(n·m) Vergleiche erforderlich, etwa wenn das Muster am und der Text an ist. Durch eine geringfügige Modifikation des Algorithmus lässt sich die Anzahl der Vergleiche aber auch im allgemeinen Fall auf O(n) begrenzen.
Ist das Alphabet groß im Vergleich zu Länge des Musters, benötigt der Algorithmus im Durchschnitt O(n/m) Vergleiche. Dies ist der Fall, weil die Schlechtes-Zeichen-Strategie häufig Verschiebungen um m ergibt.
Zusammenfassung
Der Boyer-Moore-Algorithmus verwendet zwei Strategien, um bei einem Mismatch die größtmögliche Verschiebung des Musters zu bestimmen: die Schlechtes-Zeichen-Strategie und die Gutes-Ende-Strategie. Beide Strategien können Verschiebungen um m bewirken: die Schlechtes-Zeichen-Strategie, wenn das erste verglichene Textzeichen nicht im Muster vorkommt und die Gutes-Ende-Strategie, wenn die übereinstimmenden Textzeichen nicht an anderer Stelle im Muster vorkommen.
Der Vorlauf für die Gutes-Ende-Strategie ist recht schwierig zu verstehen und zu implementieren. Daher findet man gelegentlich Versionen des Boyer-Moore-Algorithmus, in denen die Gutes-Ende-Strategie schlicht weggelassen wird. Die Begründung ist, dass die Schlechtes-Zeichen-Strategie ausreichend sei und die Gutes-Ende-Strategie nicht viele Vergleiche einspare.
Dies stimmt jedoch nur bei großen Alphabeten. Will man sich der Einfachheit halber auf die Schlechtes-Zeichen-Strategie beschränken, so sind der Horspool-Algorithmus und der Sunday-Algorithmus geeigneter.
Literatur
[BM 77] R.S. Boyer, J.S. Moore: A Fast String Searching Algorithm. Communications of the ACM, 20, 10, 762-772 (1977)
[Lan 12] H.W. Lang: Algorithmen in Java. 3. Auflage, Oldenbourg (2012)
Das Verfahren von Boyer-Moore und andere Textsuchverfahren, so etwa die Verfahren von Knuth-Morris-Pratt, Horspool und Sunday finden Sie auch in meinem Buch über Algorithmen.
Weitere Themen des Buches: Sortieren, Graphenalgorithmen, Arithmetik, Codierung, Kryptografie, parallele Sortieralgorithmen.
Themen des Buches: Sortieren, Graphenalgorithmen, Arithmetik, Codierung, Kryptografie, parallele Sortieralgorithmen.

[Web 1] http://www-igm.univ-mlv.fr/~lecroq/string/
[Web 2] http://hwlang.de/algorithmen/pattern/bmpreprocess.xls
Vorlauf für die Gutes-Zeichen-Strategie als Visualisierung in Excel
Weiter mit: [Modifizierter Boyer-Moore-Algorithmus] [Horspool-Algorithmus] oder [up]
H.W. Lang mail@hwlang.de Impressum Datenschutz
Created: 22.02.2001 Updated: 05.02.2023
Diese Webseiten sind während meiner Lehrtätigkeit an der Hochschule Flensburg entstanden