Design of a bit-serial multiplier
This paper describes the architecture of a bit-serial multiplier and its formal derivation. A 16-bit multiplier of this type has been implemented in the processor of the ISATEC Systola-1024 array processor board.
Multiplication algorithm
The following scheme describes the school method for multiplication of two n-bit numbers x and y and addition of a number s for n = 3. The generalization to arbitrary n is obvious.
| s2 | s1 | s0 | ||||||||||
| y2 | y1 | y0 | · x0 | |||||||||
| y2 | y1 | y0 | · x1 | |||||||||
| y2 | y1 | y0 | · x2 | |||||||||
| r5 | r4 | r3 | r2 | r1 | r0 | |||||||
By introducing additional variables for intermediate result bits and additional subscripts to make all variables distinct this scheme is extended to the following scheme:
| s05 | s04 | s03 | s02 | s01 | s00 | |||||
| x05 | x04 | x03 | x02 | x01 | x00 | |||||
| y05 | y04 | y03 | y02 | y01 | y00 | |||||
| c05 | c04 | c03 | c02 | c01 | c00 | |||||
| s15 | s14 | s13 | s12 | s11 | s10 | |||||
| x15 | x14 | x13 | x12 | x11 | x10 | |||||
| y15 | y14 | y13 | y12 | y11 | y10 | |||||
| c15 | c14 | c13 | c12 | c11 | c10 | |||||
| s25 | s24 | s23 | s22 | s21 | s20 | |||||
| x25 | x24 | x23 | x22 | x21 | x20 | |||||
| y25 | y24 | y23 | y22 | y21 | y20 | |||||
| c25 | c24 | c23 | c22 | c21 | c20 | |||||
| s35 | s34 | s33 | s32 | s31 | s30 | |||||
The values of the new variables of the second scheme are defined in terms of the variables of the first scheme as:
| s0j | = sj | for j ∈ {0, ..., n-1} | ||
| xi0 | = xi | for i ∈ {0, ..., n-1} | ||
| y0j | = yj | for j ∈ {0, ..., n-1} |
The intermediate result bits are defined by the following recurrence equations:
| si+1j | = (sij + xij yij + cij) mod 2 | for i ∈ {0, ..., n-1}, | j ∈ {0, ..., 2n-1} | |||
| cij+1 | = (sij + xij yij + cij) div 2 | for i ∈ {0, ..., n-1}, | j ∈ {0, ..., 2n-2} | |||
| yi+1j+1 | = yij | for i ∈ {0, ..., n-2}, | j ∈ {0, ..., 2n-2} | |||
| xij+1 | = xij | for i ∈ {0, ..., n-1}, | j ∈ {0, ..., 2n-2} |
Then we have as the result of the multiplication/addition:
| snj | = rj | for j ∈ {0, ..., 2n-1} |
Index space transformation
The next step is the transformation of the above index space {(i,j)} into the index space {(t,z)} of time and a linear array of processing elements. This is done by the method of Moldovan and Fortes [MF 86].
The data dependency matrix D of the recurrences in the index space {(i,j)} is
| s | c | y | x | |||||||
| D = | i | 1 | 0 | 1 | 0 | |||||
| j | 0 | 1 | 1 | 1 |
The data dependencies express the fact that, e.g., variable s computed at index (i,j) is next used at index (i+1,j), or variable y computed at index (i,j) is next used at index (i+1,j+1).
Now a linear transformation is chosen that transforms the index space {(i,j)} into the index space {(t,z)} of time and processors. The transformed data dependencies express the data flow in time and processor space.
With the linear transformation
| i | j | |||||
| T = | t | 1 | 1 | |||
| z | 1 | 0 |
applied to the data dependency matrix we have
| s | c | y | x | |||||||
| TD = | t | 1 | 1 | 2 | 1 | |||||
| z | 1 | 0 | 1 | 0 |
TD expresses for each variable computed at time/position (t, z) at which time and in which processor relative to (t, z) it will be used next:
Variable s is passed to the next processing element with delay 1, c is stored in each processing element for one time unit, y is passed to the next processing element with delay 2, x is stored in each processing element for one time unit.
The transformation of the index space {(i,j)} into the index space {(t,z)} of time and processors determines at which absolute time the input variables have to be at which processing element and at which absolute time the output arrives at which processing element.
For instance, x20 = x2 has to be at processing element z = 2 at time t = 2, since T·(2 0)T = (2 2)T (index pairs are assumed as column vectors). The result bit s34 = r4 has to be at processing element z = 3 (i.e. it leaves processing element 2) at time t = 7, since T·(3 4)T = (7 3)T etc. Observe that it is necessary to initialize the multiplier with 0's corresponding to the variables that have to be set to 0 in the multiplication scheme (e.g. c00 or y10).
Different transformations result in different time schedules and usage of interconnections of the processor array. The following conditions have to be satisfied for a valid transformation T:
(ZD)k > 0 for all columns k and
TD = VB
The first condition incorporates the restriction of the systolic approach that data communication requires at least one time unit. Here, Z is the first row of T (the transformation in time).
The second condition reflects the restriction that data have to travel along the connections of the processor array. Here, V is the connectivity matrix of a linear array and B is a utilization matrix of V. B says which connections of V are used by which variables of D.
The connectivity matrix V of a linear array contains (possibly among others) the connections
| p : | pass to the next processing element (z = 1) in one time unit (t = 1) , | |
| q : | pass to the next processing element (z = 1) in two time units (t = 2) and | |
| h : | hold in the same processing element (z = 0) for one time unit (t = 1) . |
This results in the following connectivity matrix:
| p | q | h | ||||||
| V = | t | 1 | 2 | 1 | ||||
| z | 1 | 1 | 0 |
With the following utilization matrix
| s | c | y | x | |||||||
| B = | p | 1 | 0 | 0 | 0 | |||||
| q | 0 | 0 | 1 | 0 | ||||||
| h | 0 | 1 | 0 | 1 |
we have
TD = VB
Matrix B says that s travels along connection p, c uses connection h, and so on.
Multiplication unit
The resulting multiplication unit is a linear array of processing elements, shown in Figure 1 for an operand length of n = 3. Each processing element performs the computation determined by the recurrence equations.
The input variable x is held in the same processor in each time step. Thus, this input has to be provided in a bit-parallel way. However, a timing analysis shows that x0 is first required at time Z(0 0)T = 0, x1 is first required at time Z(1 0)T = 1, and so on. Thus, input x can be shifted into the multiplier serially and latched at appropriate times.
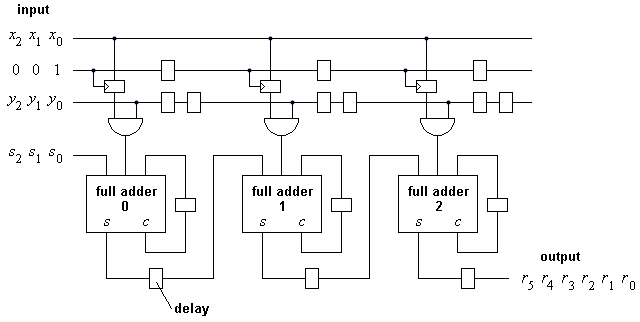
Figure 1: Bit-serial multiplier for three-bit numbers
For n-bit operands, the multiplier has an execution time of 3n cycles. It takes n cycles before the first result bit is produced at the output of the multiplier, and then another 2n cycles for output of the 2n result bits. However, successive multiplications can be pipelined in a way such that the input is provided while the last n result bits are being output. Thus, the execution time drops to 2n.
Conclusions
The bit-serial multiplier presented here is very simple. Its design is obtained in a straightforward way from the standard multiplication algorithm. For successive multiplications, its execution time is optimal since 2n cycles are necessary to produce 2n output bits bit-serially.
However, there are bit-serial multipliers that require 2n cycles for a single multiplication [Sips 82][SR 82].
References
[MF 86] D.I. Moldovan, J.A.B. Fortes: Partitioning and Mapping Algorithms into Fixed Size Systolic Arrays. IEEE Transactions on Computers C-35, 1, 1-12 (1986)
[Sips 82] H.J. Sips: Comments on "An O(n) Parallel Multiplier with Bit-Sequential Input and Output". IEEE Transactions on Computers C-31, 4, 325-327 (1982)
[SR 82] N.R. Strader, V.T. Rhyne: A Canonical Bit-Sequential Multiplier. IEEE Transactions on Computers C-31, 8, 791-795 (1982)