Codierungstheorie
Huffman-Code
Idee
In einem deutschen oder englischen Text kommt der Buchstabe e sehr viel häufiger vor als beispielsweise der Buchstabe q. Um den Text mit möglichst wenigen Bits zu codieren, liegt die Idee nahe, häufig vorkommende Zeichen durch möglichst kurze Codewörter zu codieren. Diese Idee ist auch beim Morse-Code verwirklicht, in dem das Zeichen e durch ein Codewort der Länge 1, nämlich einen ·, das Zeichen q dagegen durch ein Codewort der Länge 4, nämlich – – · – codiert wird.
Problematisch bei Codes mit unterschiedlichen Codewortlängen ist, dass im Allgemeinen eine eindeutige Dekodierung von Zeichenfolgen nicht möglich ist: Im Morse-Code könnte beispielsweise die Folge · · – · · · · – sowohl zu usa als auch idea dekodiert werden.
Das Problem kommt dadurch zustande, dass gewisse Codewörter Anfangswörter von anderen Codewörtern sind. Dadurch kann bei der Dekodierung nicht entschieden werden, wo ein Codewort endet und wo das nächste anfängt. Die o.a. Folge könnte mit e (·) oder mit i (· ·) oder mit u (· · – ) oder sogar mit f (· · – ·) anfangen.
Gilt dagegen die folgende Bedingung, so lassen sich codierte Zeichenfolgen direkt und eindeutig dekodieren. Im Morse-Code wird die Bedingung erfüllt, indem hinter jedem Codewort als Trennzeichen eine kurze Pause eingefügt wird.
Satz: (Fano-Bedingung)
Wenn kein Codewort Anfangswort eines anderen Codewortes ist, dann ist jede codierte Zeichenreihe eindeutig dekodierbar.
Gegeben sei ein Alphabet A und ein Text t ∈ A+. Ziel des Verfahrens von Huffman [Huf 52] ist die systematische Konstruktion eines Codes c(A) ⊆ 𝔹+, der die Fano-Bedingung erfüllt und der den Text mit möglichst wenigen Bits codiert.
Anwendung findet die Huffman-Codierung nicht nur bei der Kompression von Texten, sondern u.a. in der Fax-Übertragung und im Bilddaten-Kompressionsverfahren JPEG.
Konstruktion des Huffman-Codes
Das Verfahren konstruiert einen binären Baum mit einer Knotenmarkierung p und einer Kantenmarkierung h.
Algorithmus Huffman
Eingabe:
Text t
Ausgabe:
Binärer Baum mit einer Knotenmarkierung p und einer Kantenmarkierung h
Methode:
- erzeuge für jedes Zeichen x, das im zu codierenden Text t vorkommt, einen Knoten und markiere den Knoten mit der Häufigkeit, mit der x im Text vorkommt
- solange es mehr als einen Knoten gibt, zu dem keine Kante hinführt, wiederhole
- suche zwei Knoten u und v mit minimaler Markierung p(u) bzw. p(v), zu denen noch keine Kante hinführt
- erzeuge einen neuen Knoten w und verbinde w mit u und v; markiere die eine Kante mit 0, die andere mit 1; markiere den Knoten w mit p(u) + p(v)
Nach Konstruktion dieses Baumes ergibt sich für jedes Zeichen x die Codierung c(x) als Folge der Kantenmarkierungen auf dem Pfad von der Wurzel zu dem Blatt, das zu x gehört.
Weiter unten auf dieser Seite befindet sich eine JavaScript-Applikation zum Ausprobieren dieses Verfahrens.
Beispiel
Der zu codierende Text sei: im westen nichts neues
Im folgenden Bild 1 ist die Situation nach Schritt 1 des Algorithmus dargestellt. Die darauf folgenden Bilder 2 bis 5 zeigen weitere Stadien im Verlauf der Konstruktion des Baumes in Schritt 2. Die Kanten sind von oben nach unten gerichtet; die Kantenmarkierungen sind zunächst weggelassen.
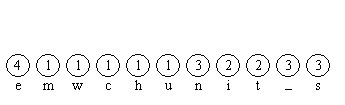
Bild 1: In Schritt 1 erzeugte Knoten
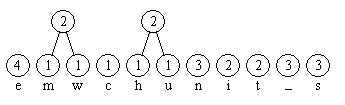
Bild 2: Die ersten beiden in Schritt 2 neu erzeugten Knoten
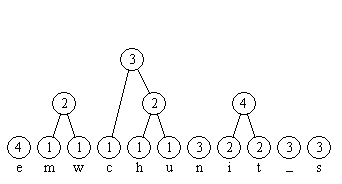
Bild 3: Weitere neu erzeugte Knoten
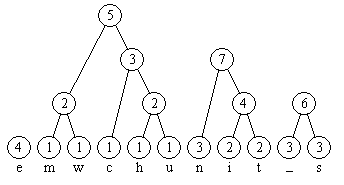
Bild 4: Weitere neu erzeugte Knoten
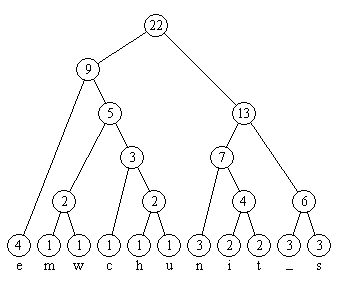
Bild 5: Der fertige Huffman-Baum
Die Knoten des Baumes lassen sich mit Mengen von Zeichen aus A identifizieren. Nach Schritt 1 besteht der Graph T = (V, E) zunächst nur aus isolierten Knoten:
V = { {x} | Zeichen x kommt im zu codierenden Text vor } .
Ein in Schritt 2 erzeugter Knoten w stellt die Menge w = u ∪ v dar, wobei u und v die beiden Nachfolgerknoten sind. Die Knotenmarkierung p(w) lässt sich als die Wahrscheinlichkeit interpretieren, mit der die Zeichen, die in w liegen, insgesamt im Text vorkommen.
Da u und v disjunkte Mengen sind, ergibt sich p(w) als Summe der Wahrscheinlichkeiten p(u) und p(v).
Im Beispiel gibt also die Markierung 4 des Knotens {e} die Wahrscheinlichkeit an, mit der das Zeichen e im Text vorkommt: nämlich 4/22; die Markierung 7 gibt an, wie oft n, i, oder t im Text vorkommen, nämlich zusammen mit der Wahrscheinlichkeit 7/22.
Huffman-Codierung und -Dekodierung
Im folgenden Bild 6 sind die Kantenmarkierungen des Baumes angegeben. Die Markierungen der Wege von der Wurzel zu den Blättern sind die Codewörter des Huffman-Codes, also z.B. 00 für e, 100 für n, 01111 für u usw.
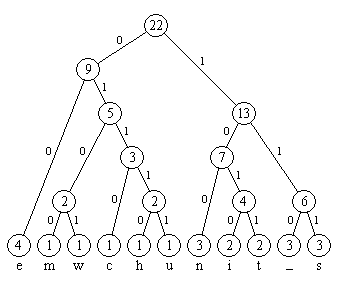
Bild 6: Kantenmarkierungen des Huffman-Baumes
Die Codierung des Textes im westen nichts neues ist:
1010010011001010011110110010011010010100110011101011111110100000111100111
Die Länge der Codierung ist 73 Bit; diese Zahl ergibt sich auch als Summe der Markierungen der inneren Knoten des Huffman-Baumes.
Der Informationsgehalt des Textes ist –  i = 0, ..., n-1 log(pi) Bit, wobei n die Länge des Textes ist und pi die Wahrscheinlichkeit, mit der das i-te Textzeichen im Text vorkommt. Mit p0 = 2/22, p1 = 1/22, p2 = 3/22 usw. ergibt sich ein Informationsgehalt von 71,84 Bit.
i = 0, ..., n-1 log(pi) Bit, wobei n die Länge des Textes ist und pi die Wahrscheinlichkeit, mit der das i-te Textzeichen im Text vorkommt. Mit p0 = 2/22, p1 = 1/22, p2 = 3/22 usw. ergibt sich ein Informationsgehalt von 71,84 Bit.
Bei Codierung der 11 verschiedenen Zeichen des Textes mit einem 4-Bit-Blockcode wären 22·4 Bit = 88 Bit erforderlich gewesen.
Der codierte Text wird dekodiert, indem der Baum von oben nach unten jeweils abhängig vom gelesenen Zeichen durchlaufen wird. Beim Erreichen eines Blattes wird das zugehörige Textzeichen ausgegeben. Anschließend wird wieder bei der Wurzel gestartet, sofern noch Zeichen zu lesen sind.
Aus dem Huffman-Baum lässt sich in ein deterministischer endlicher Automat machen, indem die Knoten als Zustände aufgefasst werden und die (von oben nach unten gerichteten) Kanten als Zustandsübergänge für die gelesenen Symbole 0 bzw. 1. Die Wurzel ist der Startzustand, an den Blättern wird jeweils das dekodierte Zeichen ausgegeben. Zusätzlich müssen von jedem Blatt noch Zustandsübergänge wieder zurück zu den beiden Folgezuständen der Wurzel eingefügt werden, wie dies in Bild 7 exemplarisch für ein Blatt angedeutet ist.
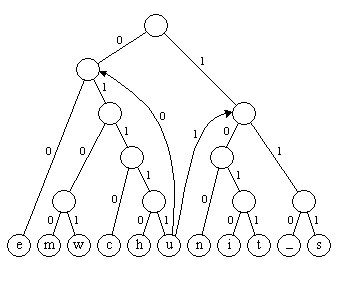
Bild 7: Aus dem Huffman-Baum konstruierter Automat (nicht alle Zustandsübergänge dargestellt)
Bei der Übertragung von Huffman-codierten Nachrichten muss im Allgemeinen die Code-Tabelle mit übertragen werden. Die Kompressionsrate ist stark von der Wahrscheinlichkeitsverteilung der zu codierenden Zeichen abhängig.
Ausprobieren
0. Text eingeben:
1. Erzeuge für jedes Zeichen des Textes einen Knoten
2. Konstruiere den Huffman-Baum (jeweils zwei Knoten mit minimaler Häufigkeit anklicken)
3. Erzeuge den Huffman-Code und codiere den Text
Literatur
[Huf 52] D.A. Huffman: A Method for the Construction of Minimum Redundancy Codes. Proceedings of the IRE, 40, 1098-1101 (1952)
[Sed 88] R. Sedgewick: Algorithms. 2. Auflage, Addison-Wesley (1988)
[Lan 12] H.W. Lang: Algorithmen in Java. 3. Auflage, Oldenbourg (2012)
Das Verfahren zur Erzeugung des Huffman-Codes finden Sie auch in meinem Buch über Algorithmen.
Weitere Themen des Buches: Sortieren, Textsuche, Graphenalgorithmen, Arithmetik, Codierung, Kryptografie, parallele Sortieralgorithmen.
Themen des Buches: Sortieren, Textsuche, Graphenalgorithmen, Arithmetik, Codierung, Kryptografie, parallele Sortieralgorithmen.

Weiter mit: [up]
H.W. Lang mail@hwlang.de Impressum Datenschutz
Created: 10.03.1997 Updated: 06.03.2023
Diese Webseiten sind während meiner Lehrtätigkeit an der Hochschule Flensburg entstanden