Asymptotic complexity | |
Upper bounds
The number of steps an algorithm requires to solve a specific problem is denoted as the running time of the algorithm. The notion of a step refers to an underlying machine model. The machine must be able to execute a single step in constant time.
In general, the running time depends on the size of the problem and on the respective input.
Example: The running time of a sorting algorithm grows if the length of the input sequence grows. If the input sequence is presorted, compared to an unsorted sequence possibly less steps are sufficient.
In order to evaluate an algorithm independently of the input, the notion of time complexity is introduced. The time complexity T(n) is a function of the problem size n. The value of T(n) is the running time of the algorithm in the worst case, i.e. the number of steps it requires at most with an arbitrary input.
Sometimes the behavior on the average is considered, i.e. the mean number of steps required with a large number of random inputs.
Example: The sorting algorithm insertion sort has a worst case time complexity of T(n) = n·(n-1)/2 comparison-exchange steps to sort a sequence of n data elements.
Often, it is not necessary to know the exact value of T(n), but only an upper bound as an estimate.
Example: An upper bound for the time complexity T(n) of insertion sort is the function f(n) = n2/2, since T(n) f(n) for all n
f(n) for all n 
 .
.
The asymptotic complexity is a function f(n) that forms an upper bound for T(n) for large n. That is, T(n)f(n) is only required for all n n0, for some n0 .
n0, for some n0 .
In general, just the order of the asymptotic complexity is of interest, i.e. if it is a linear, a quadratic or an exponential function. The order is denoted by a complexity class using the O-notation.
Definition: Let f : 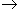
 be a function. The set O(f) is defined as follows:
be a function. The set O(f) is defined as follows:
O(f) = { g : |  c>0 n0
c>0 n0  nn0 : g(n)c·f(n) }
nn0 : g(n)c·f(n) }
In words: O(f) comprises all functions g, for which there exists a constant c and a number n0, such that g(n) is smaller or equal to c·f(n) for all nn0.
This means that O(f) is the set of all functions that asyptotically do not grow faster than f, disregarding constant factors.
Observe that O(f) is a set, therefore the correct writing is g O(f), if one wants to express that g is of the order of f (and not g = O(f) as sometimes seen).
Example: Let g(n) = 2n2 + 7n – 10 and f(n) = n2. Then
g O(f)
since with c = 3 and for nn0 = 5 we have
2n2 + 7n – 10 c·n2
Notation: It is quite common to write the functions with argument n, namely
g(n) O(f(n))
or for the function g(n) of the example
2n2 + 7n – 10 O(n2)
Example: The time complexity T(n) of insertion sort lies in the complexity class O(n2).
The set O(n2) is the complexity class of all functions that grow at most quadratically. Respectively, O(n) is the set of all functions that grow at most linearly, O(1) is the set of all functions that are bounded from above by a constant, O(nk) is the set of all functions that grow polynomially etc.
Observe the words "at most". So it is true that n O(n2), since with c = 1 and n0 = 1 it holds that nc·n2 for all nn0. Actually, we have
O(n) 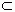 O(n2)
O(n2)
Example:
10n + 5 log(n) + 8 O(n)
8n O(n2)
65 O(1)
n1000 O(2n)
Lower bounds
Once an algorithm for solving a specific problem is found the question arises whether it is possible to design a faster algorithm or not. How can we know unless we have found such an algorithm? In most cases a lower bound for the problem can be given, i.e. a certain number of steps that every algorithm has to execute at least in order to solve the problem. As with the upper bounds the notion of a step refers to an underlying machine model.
Example: In order to sort n numbers, every algorithm at least has to take a look at every number. A sequential machine that can take a look at a number in one step therefore needs at least n steps. Thus f(n) = n is a lower bound for sorting, with respect to the sequential machine model.
Again, constant factors c and small problem sizes below some n0 are disregarded. Only the order of the lower bound is considered, namely if it is a linear, quadratic, exponential or some other function.
Again, the order is denoted by a function class.
Definition: Let f : a function. The set Ω(f) is defined as follows:
Ω(f) = { g : | c>0 n0 nn0 : g(n)c·f(n) }
In words: Ω(f) comprises all functions g, for which there exists a constant c and a number n0, such that g(n) is greater or equal to c·f(n) for all nn0.
This means that Ω(f) is the set of all functions that asymptotically grow at least as fast as f, disregarding constant factors.
Example: Let g(n) = 2n2 + 7n – 10 and f(n) = n2. Then
g Ω(f)
since with c = 1 and for nn0 = 2 we have
2n2 + 7n – 10 c·n2
This example function g(n) lies in Ω(n2) as well as in O(n2), i.e. it grows at least quadratically, but also at most quadratically.
In order to express the exact order of a function the class Θ(f) is introduced (Θ is the greek letter Theta).
Definition: Θ(f) = O(f)  Ω(f)
Ω(f)
As seen above, the lower bound for the sorting problem lies in Ω(n). Its upper bound lies in O(n2), e.g. using insertion sort. How can the gap between these two functions be bridged? Is it possible to find a tighter lower or a tighter upper bound? It turns out that both is true: it is possible to sort faster, namely in time O(n·log(n)) e.g. with heapsort, and the lower can also be improved to Ω(n·log(n)).
Therefore, heapsort is an optimal sorting algorithm, since its complexity matches the lower bound for the sorting problem.
 |
|
|